 By Francesco Sylos Labini, Nikolay L. Vasilyev, Yurij V. Baryshev
By Francesco Sylos Labini, Nikolay L. Vasilyev, Yurij V. Baryshev
Astronomy and Astrophysics, 508, 17-43 (2009)
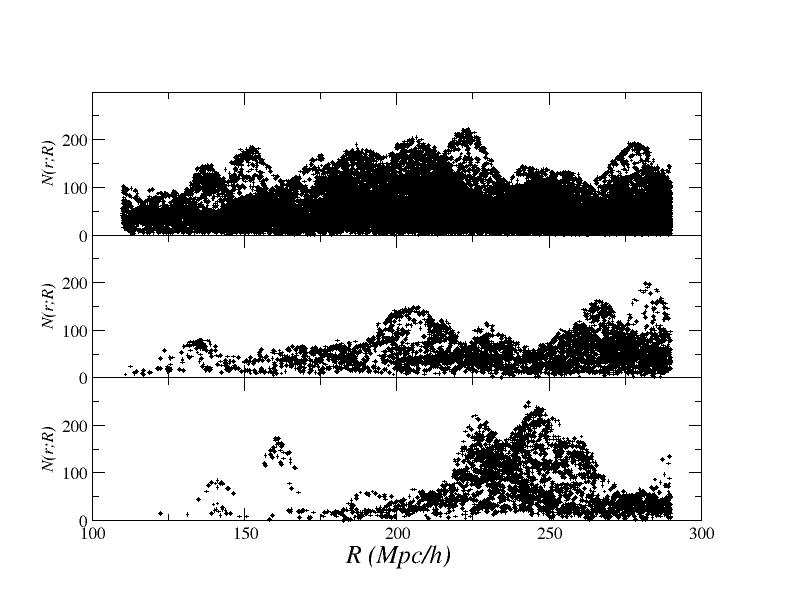
Statistical analyses of finite sample distributions usually assume that fluctuations are self-averaging, i.e. that they are statistically similar in different regions of the given sample volume. By using the scale-length method, we test whether this assumption is satisfied in several samples of the Sloan Digital Sky Survey Data Release Six. We find that the probability density function (PDF) of conditional fluctuations, filtered on large enough spatial scales (i.e., r>30 Mpc/h), shows relevant systematic variations in different sub-volumes of the survey. Instead for scales r<30 Mpc/h the PDF is statistically stable, and its first moment presents scaling behavior with a negative exponent around one. Thus while up to 30 Mpc/h galaxy structures have well-defined power-law correlations, on larger scales it is not possible to consider whole sample average quantities as meaningful and useful statistical descriptors. This situation is due to the fact that galaxy structures correspond to density fluctuations which are too large in amplitude and too extended in space to be self-averaging on such large scales inside the sample volumes: galaxy distribution is inhomogeneous up to the largest scales, i.e. r ~ 100 Mpc/h, probed by the SDSS samples. We show that cosmological corrections, as K-corrections and standard evolutionary corrections, do not qualitatively change the relevant behaviors. Finally we show that the large amplitude galaxy fluctuations observed in the SDSS samples are at odds with the predictions of the standard LCDM model of structure formation.

Leave a comment